From Theory to Code: Make Sense of Transformers in Machine Learning

Intro
I am very much aware of that there are tones of resources that cover transformers. You’ve got guides discussing the big revelations from research papers, others navigating the complex maze of math, and some breaking down the coding aspect. But here’s the thing — many of these resources tackle these aspects in isolation, making it tough to see the full picture.
My aim with this guide is different. We’ll start at the roots, delving into the core concepts presented in the pivotal research papers. From there, I’ll help you unravel the math in a way that paints a clear image, not just abstract euations. And then, to bring it all home, we’ll dive into coding these concepts.
Think of this as your all-in-one journey, connecting the dots from foundational ideas to real-world coding. My commitment is to ensure that throughout this guide, you’ll always sense the underlying link between each step.
Setting Expectation (important disclaimer)
Don’t expect an exhaustive deep dive into every aspect of transformers. Instead, think of this as your starting point, laying the groundwork for your next steps in mastering the topic. It’s about connecting the dots in a clear, logical manner so that when you delve deeper or explore further resources, everything clicks into place.
Pre-requisite Knowledge
Before we jump in, here’s what I’m hoping you’re familiar with:
- Neural Networks: The basics, like layers and neurons.
- Backpropagation: It’s how we train these networks.
- Some Pytorch: We’ll use it for our examples.
The concept of Transformer architecture was unveiled in the groundbreaking paper “Attention Is All You Need” , NIPS 2017. In the paper’s abstract, it’s clearly mentioned:
“We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.” Attention Is All You Need, NIPS 2017
From this quote, two key takeaways emerge.
- To get how Transformers work, we need to understand this attention “thing”.
- The paper also hints that the old ways (recurrence and convolutions) had some limitations, and attention helps fix them.
We’ll begin with the second point, though we won’t dive deep into it. Our aim is to clarify and provide motivation for learning about the attention mechanism which we will dicuss next, and will subsequently understand how Transformers operate.
What is Wrong with “Older” Methods (recurrence and convolutions)?
As of 2023, we might view recurrent neural networks (RNNs) and long short-term memory (LSTMs) as old-school methods for the problems Transformers tackle. However, when the “Attention Is All You Need” paper was released in NIPS 2017, these methods were the state of the art solutions for sequence modeling and transduction problems— the very problem Transformers address. But, hang on…, what exactly are sequence modeling and transduction problems?
Sequence Modeling: This is a type of problem where the objective is to predict next item in a sequence. Example: Given stock prices as $100, $101, $102, predicting the next might be $103.
Transduction Problems: Transduction refers to transforming one sequence into another sequence. A classic example is machine translation, where you transform a sentence in English to its equivalent in French.
The issue with RNNs and LSTMs
Back to our RNNs and LSTMs to understand their limitation, here is the quote from the paper:
“They generate a sequence of hidden states h(t), as a function of the previous hidden state h(t-1) and the input for position t. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.” Attention Is All You Need, NIPS 2017
Wow, that was mouthful! But in simple words this tells us that RNNs and LSTMs work step by step. For each new piece of input, they consider the previous step’s result. Because they operate this way, you can’t process multiple parts of the input all at once. This step-by-step approach slows things down, especially with longer sequences. Also, when the sequences are long, you can’t easily handle many of them at the same time due to memory limitations. So it is mostly around sequence length and parallelization!
I like to think of how an RNN reads a book (or any sequence) in a step-by-step manner, similar to how we read word by word or sentence by sentence. The RNN starts with the first word of the book. For this first word, it generates an internal note (hidden state) summarizing what it has “understood” so far. Moving to the second word, the RNN considers both this new word and the previous note (hidden state) it made for the first word. It then updates its internal note based on this combined information. The RNN continues this process, reading one word at a time, always considering its most recent note (hidden state) along with the new word to update its understanding.
Here is where the memory problem arises! That is due to the nature of how RNNs operate and the practical constraints of computational hardware. Let’s break it down:
- Lengthy Sequences: If the book (sequence) is very long, the RNN’s internal note (hidden state) needs to encapsulate all the previous information. For extremely long sequences, it becomes challenging for the RNN to retain and manage all the past details.
- Backpropagation Through Time (BPTT): During training, for the RNN to learn and adjust its weights, we use BPTT. This process requires retracing our steps through each element of the sequence to update the model’s weights based on its errors. The longer the sequence, the more steps to retrace, which means more calculations and more memory usage. It’s like needing more space to store details of every step of a task for later review.
- Batching: To make training efficient, we usually process multiple sequences at once (batching). If each sequence is long and we’re trying to process several simultaneously, the memory usage multiplies. The quote from the paper specifically mentions “memory constraints limit batching across examples”. This means that, with long sequences, you can’t batch as many sequences together due to memory limitations, slowing down the training process.
- Vanishing and Exploding Gradient Problem: As we train an RNN using BPTT, we calculate how the error changes with respect to each weight in the network (this is what a gradient tells us). We use this information to update our weights to make our model better. When sequences are long, these gradients can get very small (vanish) or very large (explode) as they’re propagated backwards through the sequence. If they vanish, the weights aren’t updated much, and the network can’t learn long-range dependencies. This means the RNN forgets what it saw a few steps back. If they explode, the weights can be updated too aggressively, causing instability in learning.
Self-Attention (forget about Transformers for now)
Now, let’s unveil the backbone of the transformers, Self-Attention! And it’s not just the backbone; it wouldn’t be an exaggeration to say it’s the essence of the transformer. After all, the paper’s title is ‘Attention Is All You Need’! But still self-attention is not the exact equivalent to the transformer! Transformer is however as a model relying entirely on self-attention.
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution. Attention Is All You Need, NIPS 2017
So, for now, forget about Transformers, let us learn this Attention, self-attnetion, intra-attention……..!!!! But, wait! are these the same? It seems like the authors are hinting that ‘attention’ and ‘self-attention’ aren’t quite the same thing. They mentioned that Self-attention is an attention mechanism!! If that is the same that would be like saying rain is wet:
“Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.” Attention Is All You Need, NIPS 2017
So, let’s clarify at the high level:
Attention: This is a mechanism that lets a model focus on certain parts of one sequence when processing another. Think of it as the model asking, “Which parts of the input sequence should I look at when working on this part of the output?”
Self-Attention: This is when a sequence pays attention to itself. Instead of looking at another sequence, the model looks at other positions within the same sequence. It’s like the model asking, “Which parts of this sequence are important in relation to this specific part?”
So, while both deal with focusing on relevant parts, the key difference is whether the attention is directed at another sequence (attention) or within the same sequence (self-attention).
The Pillars of Attention: Query, Key, and Value
When we deal with words in natural language processing (NLP), we often convert them into vectors, commonly known as word embeddings. These embeddings capture the semantics of the word itself. For example, the word “apple” will have an embedding representing it, which is invariant to its use in any sentence, whether we’re talking about “apple fruit” or “Apple Inc.”
To address this limitation, the self-attention mechanism can help. It aims to give words a new representation that not only captures their inherent meaning but also reflects their context within a given sentence.
The self-attention mechanism operates using three primary components: the Query (Q), the Key (K), and the Value (V). They are all vectors for each word or token in a sequence. However, when we consider an entire sequence or batch of sequences, these vectors are organized into matrices.
What and Why Q, K, and V??!
- These vectors have unique roles. The Query seeks specific information in the input. The Key responds to these queries. The Value delivers the content we aim to focus on, based on the alignment between Query and Key.
- Transforming the initial embeddings to Q, K, and V means the model isn’t tied down to the static meanings of the original embeddings. It can learn representations more suited for the attention mechanism.
How are these Q, V and K formed?!
Step 1: We start with an input representation of our sequence, typically a matrix where each row corresponds to a word or token’s embedding.
For a given sequence, each token gets an embedding, a vector representation. Let’s say our sequence has N tokens and each token's embedding is of dimension d_embed. Our input matrix, therefore, has a size of N x d_embed.
Let’s look at the mini-sentence, “I love cats.” Each word is given an initial embedding ( I call them initial as they are the invariant ones to the sentence) :
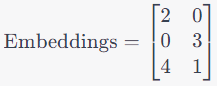
Step 2: Each token’s embedding undergoes three separate linear transformations to generate Q, K, and V vectors:
Q = Embedding x W_Q
K = Embedding x W_K
V = Embedding x W_V
Here, W_Q, W_K, and W_V are weight matrices specific to Queries, Keys, and Values respectively. Suppose we have these initial weight matrices, normally these weight matrices are initiated randomly:
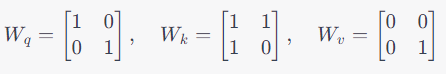
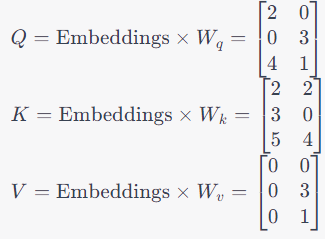
Matrix Q, contains the Q vectors of all 3 words, Matrix K, contains the K vectors of all 3 words and Matrix V, contains the V vectors of all 3 words.
You might be thinking now, these matrices are so Hugh if we have large text or embedding vectors and you are definitely right, welcome to the L(arge)LMs world !! This was the end of step 2.
Step 3: Then we calculate what we call attention scores. This attention score should tell us how much each word should focus on every other word in the sequence.
This is achieved by taking the dot product of the Q vector of a word with the K vector of every other word, including itself (forget about the V matrix for a moment).
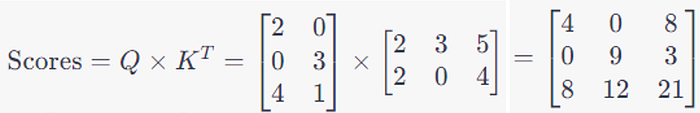
Step 4: Then we apply Softmax, in other words normalization to scale down each row of the scores matrix:
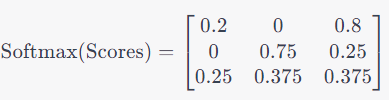
Step 5: The final step is to compute the new embeddings. Multiply the softmax scores with the V matrix:


The final output: The resulting matrix provides the new contextual embeddings for the words “I”, “love”, and “cats”. The representations are no longer solely about the words themselves but encapsulate information about their context within the sentence.
So in short in the self-attention mechanism:
- Query (Q) represents each word’s “question” about its context within a sentence.
- Key (K) provides an “index” of how other words can answer these questions.
- By dot-producting Q and K, we compute attention scores, determining how much each word should attend to every other word.
- Value (V) vectors then supply the actual content or “answer” from the attended words.
For our sentence “I love cats”:
- “Love” asks about its context via its Q vector.
- The K vectors of “I” and “cats” help quantify their relevance to “love”.
- The attention scores then weigh the V vectors of “I” and “cats” to create a context-rich representation for “love”.
In essence, Q and K decide the attention’s weight, and V provides the contextual content.
If you peek to the “Attention Is All You Need” paper you will find this is illustrated in this figure, using the term Scaled Dot-Product Attention:
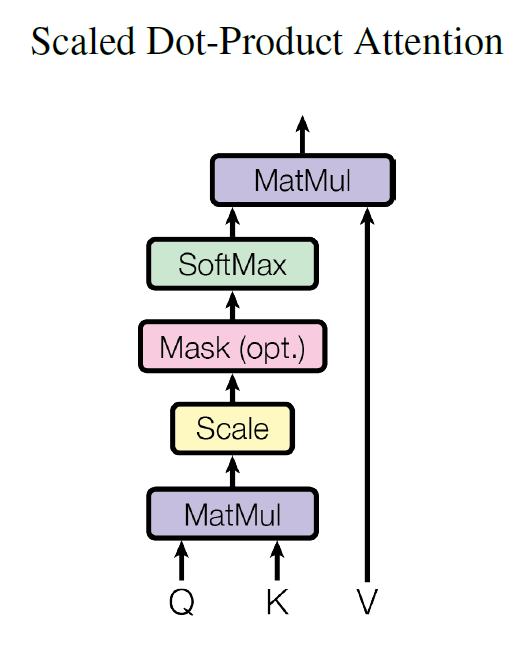
A very simple illustrative code to make it even clearer:
import torch
import torch.nn.functional as F
# Sample embeddings for "I love cats"
word_embeddings = {
"I": [1, 2, 3],
"love": [4, 5, 6],
"cats": [7, 8, 9]
}
# Convert embeddings to PyTorch tensors
sentence = ["I", "love", "cats"]
embeddings = [word_embeddings[word] for word in sentence]
embeddings = torch.tensor(embeddings, dtype=torch.float32)
# Initialize weights for Q, K, V
d_model = 3 # size of embeddings
Wq = torch.randn(d_model, d_model, requires_grad=True)
Wk = torch.randn(d_model, d_model, requires_grad=True)
Wv = torch.randn(d_model, d_model, requires_grad=True)
# Define a simple optimizer
optimizer = torch.optim.SGD([Wq, Wk, Wv], lr=0.01)
# === FORWARD PASS ===
# Compute Q, K, V
Q = embeddings @ Wq
K = embeddings @ Wk
V = embeddings @ Wv
# Compute attention scores
attn_scores = Q @ K.t()
attn_scores = F.softmax(attn_scores, dim=-1)
# Compute weighted V to get contextual embeddings
contextual_embeddings = attn_scores @ V
# Just for this example: synthetic "target" embeddings and loss
# (In a real-world example, you would have some downstream task to generate loss)
target_embeddings = torch.randn(3, 3)
loss = F.mse_loss(contextual_embeddings, target_embeddings)
# === BACKWARD PASS ===
# Backpropagation
loss.backward()
# Gradient Descent
optimizer.step()
print("Updated Wq:", Wq)
print("Updated Wk:", Wk)
print("Updated Wv:", Wv)Multi-head Attention
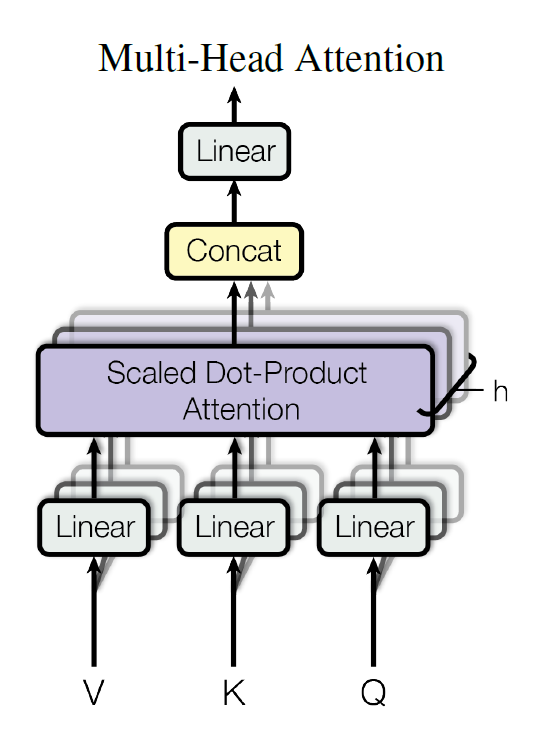
It is an extension of the standard self-attention mechanism, allowing the model to focus on different parts of the input for different tasks or purposes simultaneously. Instead of having one set of attention weights (as in the basic self-attention), multi-head attention has multiple sets, or “heads.”
Conceptually, in the “standard” self-attention mechanism, we compute a single set of Query, Key, and Value matrices and get one set of attention scores. This single set of scores may focus on one particular aspect or pattern in the data.
With multi-head attention, we do this multiple times in parallel, resulting in multiple sets of attention scores. Each head might learn to focus on a different pattern or aspect in the data.
Why multi-head attention? It enables the model to grasp various facets of information simultaneously, like syntax, semantics, and tone in language processing.
Mathematically, For each head, distinct weight matrices are used: Wq, Wk, and Wv. The attention outputs from all heads are concatenated and linearly transformed for the final output.
How the authours visualizes this multi-head attnetion is in this Fig:
Back to Transformers!
Now let us back to out Transformers to see how this attention mechanism has been utilized to build a Transformer model.
Many of the top-performing models for processing sequences have an encoder-decoder setup. In this setup, the encoder takes an input sequence of symbols (like words) and turns it into continuous values. The decoder then uses these values to produce a new sequence, building each part based on its prior outputs.
The Transformer model, discussed in the “Attention Is All You Need” paper, follows this encoder-decoder framework. However, it stands out by using layers of self-attention and straightforward fully-connected networks in both parts. This structure is illustrated in the paper’s figure, splitting the encoder on the left and the decoder on the right.

We really need to look closely at this picture and what’s in it. It seems more complex than the discussion we had about “Query, Key, Value” and self-attention. Let’s try following the paper and try make sense of it in term of making more explanation, intuition and code.
Encoder (the left half)
The encoder architecture in the original paper has 6 identical layers stacked on top of each other. Every layer consists of two main parts:
- Multi-head self-attention mechanism: This lets our model focus on multiple important parts of the input simultaneously.
- Feed-forward network: A basic neural layer that further processes our data.
To ensure the model not to lose any data details as it moves through the layers, there’s a shortcut (known as a residual connection). This connection takes the original data and combines it with the layer’s output. If you’re looking at a diagram above, this is represented by skipping arrows that end on the “Add & Norm” blocks. After this step, to make the data consistent and balanced, it goes through a normalization layer.
Wrapping it (the encoder part) up, every layer, including the embedding ones, provides outputs in a specific format: 512 dimensions. Sometimes it make sense to see a high level code (this is not a working code!), think of it as some sort of pseudocode representation of the encoder in Python. We can think of something like this:
def transformer_encoder(input_sequence, N=6, dmodel=512):
# Initial embeddings (assumed to be provided, can be word embeddings + positional encoding)
x = embedding_layer(input_sequence)
for i in range(N):
x = encoder_layer(x, dmodel)
return x
def encoder_layer(x, dmodel):
# First sub-layer: multi-head self-attention
attention_output = multi_head_self_attention(x, dmodel)
# Residual connection and layer normalization
x = layer_norm(x + attention_output)
# Second sub-layer: positionwise feed-forward network
feedforward_output = positionwise_feed_forward(x, dmodel)
# Residual connection and layer normalization
x = layer_norm(x + feedforward_output)
return x
def multi_head_self_attention(x, dmodel):
# This function will compute multi-head self-attention.
# For simplicity, the internal workings are abstracted here.
# It takes in the input sequence x and dmodel and returns the attention output.
...
return attention_output
def positionwise_feed_forward(x, dmodel):
# This function will compute the feed-forward network.
# For simplicity, the internal workings are abstracted here.
# It takes in the input sequence x and dmodel and returns the feed-forward output.
...
return feedforward_output
def layer_norm(input):
# This function applies layer normalization.
# For simplicity, the internal workings are abstracted here.
# It takes in the input and returns the normalized output.
...
return normalized_output
def embedding_layer(input_sequence):
# This function returns the initial embeddings for the input sequence.
# It's assumed that this might be a combination of word embeddings and positional encodings.
...
return embeddingsDecoder (the right half)
The decoder is built similarly to the encoder, with 6 identical layers. But here’s the catch: in addition to the two main parts in the encoder (multi-head self-attention and feed-forward network), the decoder has a third part that focuses on the encoder’s output.
Just like in the encoder, the decoder uses residual connections to combine the original data with the layer’s output. This is then made consistent using a normalization layer.
One special thing about the decoder is its “no peeking” rule, this is not the scientific name of the rule, it is called masking. This means that when the decoder is trying to predict a certain word, it can’t look at future words. In other words, for any given spot, it only uses information from previous positions to make predictions. This ensures our model doesn’t cheat by looking ahead! Here’s a high-level pseudocode representation of the decoder in Python:
def transformer_decoder(input_sequence, encoder_output, N=6, dmodel=512):
# Initial embeddings (assumed to be provided, which could be word embeddings + positional encoding)
x = embedding_layer(input_sequence)
for i in range(N):
x = decoder_layer(x, encoder_output, dmodel)
return x
def decoder_layer(x, encoder_output, dmodel):
# First sub-layer: masked multi-head self-attention
attention_output = masked_multi_head_self_attention(x, dmodel)
# Residual connection and layer normalization
x = layer_norm(x + attention_output)
# Second sub-layer: multi-head attention over encoder's output
encoder_attention_output = multi_head_attention(x, encoder_output, dmodel)
# Residual connection and layer normalization
x = layer_norm(x + encoder_attention_output)
# Third sub-layer: positionwise feed-forward network
feedforward_output = positionwise_feed_forward(x, dmodel)
# Residual connection and layer normalization
x = layer_norm(x + feedforward_output)
return x
def masked_multi_head_self_attention(x, dmodel):
# This function will compute masked multi-head self-attention.
# It ensures that position i can't attend to subsequent positions.
...
return attention_output
def multi_head_attention(x, encoder_output, dmodel):
# This function computes multi-head attention over the encoder's output.
...
return encoder_attention_output
# The remaining functions (layer_norm, positionwise_feed_forward, and embedding_layer) can be
# re-used from the encoder pseudocode provided previously.Then the transformer model should be something like:
class Transformer:
def __init__(self):
self.transformer_encoder= Encoder()
self.transformer_decoder= Decoder()
def forward(self, source, target):
encoder_output = self.transformer_encoder.forward(source)
decoder_output = self.transformer_decoder.forward(target, encoder_output)
return decoder_output
# Usage (pseudocode)
transformer = Transformer()
output = transformer(source_data, target_data)A recap Question regarding Attention:
So, how/where is this Attention applied in the transformer?
Here is what I understood when the authors listed those applications:
The Transformer model uses “multi-head attention” in three main ways:
- Encoder-Decoder Attention:
- This is where the decoder (part of the model that produces output) looks at what the encoder (part of the model that takes in the input) has processed.
- The decoder uses information from its last layer and combines it with what the encoder has produced.
- This helps the decoder to consider the entire input sequence while producing the output.
2. Encoder Self-Attention:
- Here, the encoder looks at its own previous output.
- Each part of the encoder output can check and compare with all other parts of its own output from the previous layer.
3. Decoder Self-Attention:
- Just like the encoder, the decoder also looks at its own previous outputs.
- However, there’s a catch: the decoder should only look at previous outputs or at the current output, but not at future outputs. This is to maintain a certain property in the model.
- To ensure this, some connections that would give away future information are blocked.
Other Structural Components
Feed-Forward Networks in Transformers
Each layer in the transformer model, both in the input-taking part (encoder) and the output-making part (decoder), has an additional structure as described by the authors. This structure is a simple network that processes each part of the data one by one in the same way. Think of it as applying the same mini-calculation to every piece of data. This network uses a function that involves two steps with a special operation called ReLU in between.
Embeddings
The authors explain that the transformer changes the input and output words or symbols into special lists of numbers, called vectors. This change helps the computer to understand and process them. The model also uses an additional step to predict the next word or symbol in a sequence. Interestingly, some parts of the model use the same set of numbers, and these numbers are adjusted by a specific value for better results.
Positional Encoding
The transformer model is unique because it doesn’t look back at previous steps or scan the data in ways that other models do. So, to understand the order of words or symbols, the authors introduced “positional encodings”. This provides the model with information about where each word or symbol stands in the sequence. These positional encodings use wave-like functions (sine and cosine) based on the position of the word or symbol. The authors chose this method because they believed it would help the model focus better on relative positions.
They also tested another method where the model learns the positional information on its own. Both methods provided almost the same results. However, the authors preferred the wave-like functions because they might help the model work even with longer sequences than what it was trained on.
Code
So far we understand that the transformer is not merely a self-attention mechanism but a complete architecture. Its versatility allows it to be employed in a multitude of applications. A prime example of its ease of use can be seen in tasks like text classification and sentiment analysis.
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
# Self-attention mechanism
def __init__(self, k):
super(SelfAttention, self).__init__()
# k: Dimension of the model embeddings
# Linear layers for query, key, and value of size (k, k)
self.key = nn.Linear(k, k)
self.query = nn.Linear(k, k)
self.value = nn.Linear(k, k)
def forward(self, x):
# x: Input tensor of shape (batch_size, seq_length, k)
# Applying linear transformations
key = self.key(x)
query = self.query(x)
value = self.value(x)
# Compute attention scores as dot products
scores = torch.bmm(query, key.transpose(1, 2)) / (key.size(-1) ** 0.5)
# Convert scores to probabilities using softmax
attn_probs = F.softmax(scores, dim=-1)
# Weight values using attention probabilities
weighted = torch.bmm(attn_probs, value)
return weighted
class EncoderBlock(nn.Module):
def __init__(self, k):
super(EncoderBlock, self).__init__()
# Self-attention mechanism
self.attention = SelfAttention(k)
# Layer normalization layers of size (k)
self.norm1 = nn.LayerNorm(k)
self.norm2 = nn.LayerNorm(k)
# Feed-forward network with input and output of size (k)
self.ff = nn.Sequential(
nn.Linear(k, 4*k),
nn.ReLU(),
nn.Linear(4*k, k)
)
def forward(self, x):
# x: Input tensor of shape (batch_size, seq_length, k)
# Apply self-attention
attended = self.attention(x)
x = self.norm1(attended + x)
x = self.norm2(self.ff(x) + x)
return x
class DecoderBlock(nn.Module):
def __init__(self, k):
super(DecoderBlock, self).__init__()
# Self-attention mechanism
self.attention = SelfAttention(k)
# Layer normalization of size (k)
self.norm = nn.LayerNorm(k)
# Feed-forward network
self.ff = nn.Sequential(
nn.Linear(k, 4*k),
nn.ReLU(),
nn.Linear(4*k, k)
)
def forward(self, x):
# Apply self-attention and feed-forward network
attended = self.attention(x)
x = self.norm(attended + x)
x = self.ff(x)
return x
class Transformer(nn.Module):
def __init__(self, k, depth, seq_length, num_tokens, num_classes):
super(Transformer, self).__init__()
# Token embedding: Converts token indices to vectors of size k
self.token_emb = nn.Embedding(num_tokens, k)
# Positional embedding: Gives the model a sense of token order
self.pos_emb = nn.Embedding(seq_length, k)
# Encoder and decoder blocks
self.encoder = nn.Sequential(*[EncoderBlock(k) for _ in range(depth)])
self.decoder = nn.Sequential(*[DecoderBlock(k) for _ in range(depth)])
# Final linear layer: Converts vectors of size k to class probabilities
self.to_probs = nn.Linear(k, num_classes)
def forward(self, x):
# x: Input tensor of shape (batch_size, seq_length)
# Convert token indices to vectors
tokens = self.token_emb(x)
positions = torch.arange(len(x)).unsqueeze(1)
x = tokens + self.pos_emb(positions)
# Pass input through encoder and decoder
x = self.encoder(x)
x = self.decoder(x)
# Convert the output to class probabilities
x = self.to_probs(x.mean(dim=1))
return F.log_softmax(x, dim=1)Conclusion
We’ve covered a lot and navigated the expansive world of transformers together. The world of transformers, like all of machine learning, is vast and ever-evolving. Use this guide as a foundation, and from here ask more questions, and keep learning. The potential is immense, and your journey in mastering transformers has only just started. Dive in, experiment, and let the curiosity guide your path.
